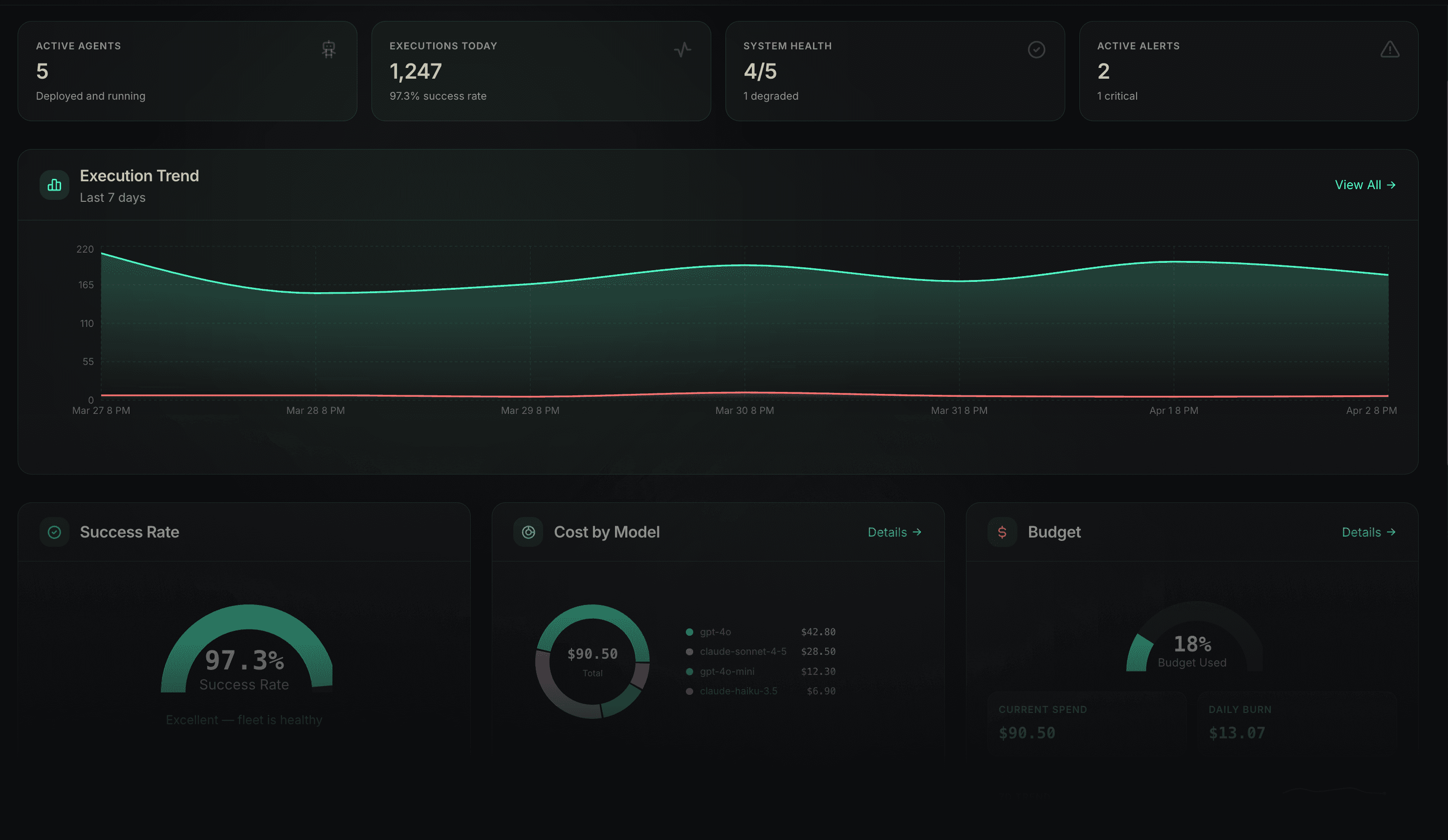
Your agents are already running.
Does anyone know what they're actually doing?
Your agents are already running.
Does anyone know what they're actually doing?
Waxell gives engineering and security teams complete visibility into every AI agent, model call, and agentic workflow — before something goes wrong.
Free to start. 2-line setup.

SOC 2 Ready
200+ libraries auto-instrumented
OpenTelemetry-native
SOC 2 type II
HIPAA • SOC II
PCI-DSS Profiles
MCP Server governance
US or EU data residency
Your agents are already running.
Does anyone know what they're actually doing?
Waxell gives engineering and security teams complete visibility into every AI agent, model call, and agentic workflow — before something goes wrong.
Free to start. 2-line setup.
200+ libraries auto-instrumented
OpenTelemetry-native
HIPAA • SOC II
PCI-DSS Profiles
MCP Server governance
US or EU data residency
AI agents are already causing real damage.
Here's what it looks like.
Here's what it looks like.
PII EXPOSURE
Your agents are leaking customer data.
You just don't know which ones yet.
Any agent that touches a database, inbox, CRM record, or document store will eventually encounter PII — and send it somewhere it shouldn't go. Without active scanning at the point of execution, you won't know it happened until a customer, an auditor, or a regulator tells you.
Waxell's Answer
Observe detects and redacts PII in real time, before it leaves the workflow.
COST BLOWOUTS
One looping agent can generate a $40,000 bill before anyone notices.
Agentic workflows don't have natural stopping points. A misconfigured tool call, a hallucinated retry loop, or an unexpected input can send token consumption exponential — and your cloud bill won't reflect it until the end of the month.
Waxell's Answer
Observe enforces budget limits per agent, per user, and per session in real time.
MCP RUG PULLS
The tool your agent trusted yesterday isn't the same tool it's running today.
MCP servers can silently change their tool descriptions — expanding permissions, altering behavior, redirecting outputs. Your agent can't tell the difference. Your team won't either, until something goes wrong downstream and the original tool description is already gone.
Waxell's Answer
Waxell Gateway fingerprints every MCP tool and alerts you when a description changes .
SHADOW AI
Most of the AI running inside your organization has never been reviewed, approved, or logged.
By mid-2026, the average knowledge-worker laptop runs Claude Desktop, Cursor, GitHub Copilot, ChatGPT, Notion AI, and personal MCP servers — all making inference calls over HTTPS, all indistinguishable from normal web traffic. IT has no record. Security has no control.
Waxell's Answer
Waxell Endpoints discovers AI apps on every device — without decrypting a single payload.
PII EXPOSURE
Your agents are leaking customer data.
You just don't know which ones yet.
Any agent that touches a database, inbox, CRM record, or document store will eventually encounter PII — and send it somewhere it shouldn't go. Without active scanning at the point of execution, you won't know it happened until a customer, an auditor, or a regulator tells you.
Waxell's Answer
Observe detects and redacts PII in real time, before it leaves the workflow.
MCP RUG PULLS
The tool your agent trusted yesterday isn't the same tool it's running today.
MCP servers can silently change their tool descriptions — expanding permissions, altering behavior, redirecting outputs. Your agent can't tell the difference. Your team won't either, until something goes wrong downstream and the original tool description is already gone.
Waxell's Answer
Waxell Gateway fingerprints every MCP tool and alerts you when a description changes .
COST BLOWOUTS
One looping agent can generate a $40,000 bill before anyone notices.
Agentic workflows don't have natural stopping points. A misconfigured tool call, a hallucinated retry loop, or an unexpected input can send token consumption exponential — and your cloud bill won't reflect it until the end of the month.
Waxell's Answer
Observe enforces budget limits per agent, per user, and per session in real time.
SHADOW AI
Most of the AI running inside your organization has never been reviewed, approved, or logged.
By mid-2026, the average knowledge-worker laptop runs Claude Desktop, Cursor, GitHub Copilot, ChatGPT, Notion AI, and personal MCP servers — all making inference calls over HTTPS, all indistinguishable from normal web traffic. IT has no record. Security has no control.
Waxell's Answer
Waxell Endpoints discovers AI apps on every device — without decrypting a single payload.
A dashboard after the fact is not governance.
It's an autopsy.
A dashboard after the fact is not governance.
It's an autopsy.
A dashboard after the fact is not governance.
It's an autopsy.
One platform.
Total visibility across every agent in your stack.
Total visibility across every agent in your stack.
Waxell instruments what you build, connects what you buy, and gives you a runtime layer for the workflows that can't afford to be wrong. All from a single observability plane.
One platform.
Total visibility across every agent in your stack.
Total visibility across every agent in your stack.
Waxell instruments what you build, connects what you buy, governs every MCP tool call,
discovers the AI running on your team's laptops, and gives you a runtime layer for the
workflows that can't afford to be wrong. One control plane, from SDK to endpoint.
Connect
AI Tool Coordination
MCP governance — policy checks, PII scanning, and audit trails on every tool call
Rug pull detection — alerts the moment a tool's capabilities change, before your agent acts on the new behavior
Human-in-the-loop inbox — escalation and delegation routing for approvals and interventions
Zero code, zero SDK — works with agents already running; no instrumentation required
Governs third-party agents via any MCP-compatible interface
Works with: Claude, GPT-4, Gemini, custom agents, and any MCP-compatible server.
Gateway
MCP Tool Governance
One URL per tenant — replaces every upstream MCP config with a single governed endpoint
Policy gate on every tool call — PII scanning, approval holds, and access controls enforced before the agent gets a response
Fingerprint system — detects tool description changes (rug pulls) before any agent calls them
160+ upstream connectors — Salesforce, GitHub, Slack, and everything else your agents reach
Human-in-the-loop — risky actions park for approval; self-hosted option runs the same image in your VPC
Works with: Claude Desktop, Claude Code, Cursor, and any MCP-compatible client.
Observe
Observability + Governance SDK
Captures every LLM call, tool invocation, and agent decision — full execution trace, not just logs
Enforces runtime policies before the next step executes — governance that acts, not just reports
50+ policy categories out of the box: Cost, Safety, Content, PII, Kill switches, Audit, and more
Auto-instrumentation — 2 lines of code, 200+ supported libraries
Works with any Python agent framework — no code changes required
Supports: LangChain, CrewAI, AutoGen, LlamaIndex, Semantic Kernel, and 12+ other frameworks.
Endpoints
Shadow AI Discovery & Governance
Discovers every AI app on every device — Claude Desktop, Cursor, Copilot, ChatGPT, browser assistants — per user, per machine
Metadata attribution without decryption — reads the TLS handshake, not the payload. Which process, which provider, which user, when.
Three postures — observe-only (default), block, or capture with on-device PII redaction
Humans and agents alike — sees a person in ChatGPT and an autonomous CLI agent calling a model
Fleet deployment via MDM — Hexnode, Jamf, Kandji, Mosyle, or Intune. Zero end-user action. macOS today, Windows rolling out.
Discovers every AI app on every device — Claude Desktop, Cursor, Copilot, ChatGPT, browser assistants — per user, per machine
Metadata attribution without decryption — reads the TLS handshake, not the payload. Which process, which provider, which user, when.
Three postures — observe-only (default), block, or capture with on-device PII redaction
Humans and agents alike — sees a person in ChatGPT and an autonomous CLI agent calling a model
Fleet deployment via MDM — Hexnode, Jamf, Kandji, Mosyle, or Intune. Zero end-user action. macOS today, Windows rolling out.
Platforms: macOS (signed, Apple-notarized) · Windows (rolling out).
Runtime
Governed Execution Layer
Policy enforcement native to every step — not layered on top after the fact
Durable execution — agents survive deploys, restarts, and workflows that run for hours or days
Spawn, suspend, resume, and replay any agent run — with optional prompt, model, or policy substitution
Full lineage causality graph — trace exactly which agent spawned which action and why
Isolated execution, durable checkpoints, kill switches at every level
Built for: financial automation, healthcare workflows, infrastructure operations — any workflow where wrong is expensive.
Connect
AI Tool Coordination
MCP governance — policy checks, PII scanning, and audit trails on every tool call
Rug pull detection — alerts the moment a tool's capabilities change, before your agent acts on the new behavior
Human-in-the-loop inbox — escalation and delegation routing for approvals and interventions
Zero code, zero SDK — works with agents already running; no instrumentation required
Governs third-party agents via any MCP-compatible interface
Works with: Claude, GPT-4, Gemini, custom agents, and any MCP-compatible server.
Observe
Observability + Governance SDK
Captures every LLM call, tool invocation, and agent decision — full execution trace, not just logs
Enforces runtime policies before the next step executes — governance that acts, not just reports
50+ policy categories out of the box: Cost, Safety, Content, PII, Kill switches, Audit, and more
Auto-instrumentation — 2 lines of code, 200+ supported libraries
Works with any Python agent framework — no code changes required
Supports: LangChain, CrewAI, AutoGen, LlamaIndex, Semantic Kernel, and 12+ other frameworks.
Runtime
Governed Execution Layer
Policy enforcement native to every step — not layered on top after the fact
Durable execution — agents survive deploys, restarts, and workflows that run for hours or days
Spawn, suspend, resume, and replay any agent run — with optional prompt, model, or policy substitution
Full lineage causality graph — trace exactly which agent spawned which action and why
Isolated execution, durable checkpoints, kill switches at every level
Built for: financial automation, healthcare workflows, infrastructure operations — any workflow where wrong is expensive.
Gateway
MCP Tool Governance
One URL per tenant — replaces every upstream MCP config with a single governed endpoint
Policy gate on every tool call — PII scanning, approval holds, and access controls enforced before the agent gets a response
Fingerprint system — detects tool description changes (rug pulls) before any agent calls them
160+ upstream connectors — Salesforce, GitHub, Slack, and everything else your agents reach
Human-in-the-loop — risky actions park for approval; self-hosted option runs the same image in your VPC
Works with: Claude Desktop, Claude Code, Cursor, and any MCP-compatible client.
Endpoints
Shadow AI Discovery & Governance
Discovers every AI app on every device — Claude Desktop, Cursor, Copilot, ChatGPT, browser assistants — per user, per machine
Metadata attribution without decryption — reads the TLS handshake, not the payload. Which process, which provider, which user, when.
Three postures — observe-only (default), block, or capture with on-device PII redaction
Humans and agents alike — sees a person in ChatGPT and an autonomous CLI agent calling a model
Fleet deployment via MDM — Hexnode, Jamf, Kandji, Mosyle, or Intune. Zero end-user action. macOS today, Windows rolling out.
Platforms: macOS (signed, Apple-notarized) · Windows (rolling out).
Governance that acts.
Governance that acts.
Set policies once. Waxell enforces them on every agent run, before the next step executes — at sub-millisecond latency.

Works inside the stack you already use.
Works inside the stack you already use.
Waxell instruments the frameworks your agents are built on — no rip-and-replace, no vendor lock-in.














200+ libraries auto-instrumented · OpenTelemetry-native
Works alongside your existing APM · Self-hosted or cloud (US or EU)

Shadow AI is the
new Shadow IT.
Shadow AI is the
new Shadow IT.
Shadow AI is the new Shadow IT.
In the 2010s, employees bypassed IT to use Dropbox, Slack, and Google Docs. Companies scrambled to govern what they couldn't see.
Today, developers are shipping AI agents without waiting for security review. Product teams are connecting third-party AI tools that operate outside any monitoring system. Entire agentic workflows are running in production with no audit trail. The risk isn't that AI will replace your team. It's that your team is already using AI in ways you can't see, measure, or control. Waxell is governance infrastructure for the agentic era.
The teams that govern AI well now will be the ones trusted to scale it.
Waxell is how you build that foundation.
2-line setup. Works with any Python agent framework.

FAQ
What is AI agent governance?
AI agent governance is the practice of controlling, monitoring, and enforcing policy over AI agents running in production — covering what they're allowed to do, how much they're allowed to spend, what data they can access, and who can override or halt them. Waxell implements AI agent governance through a runtime policy engine that evaluates agent behavior before each execution step and returns structured enforcement: retry, escalate, or halt.
What's the difference between AI agent observability and AI agent governance?
AI agent observability is the ability to see what an agent did — capturing traces, LLM calls, tool invocations, token usage, and decision points. AI agent governance is the ability to control what an agent can do — enforcing policies, blocking actions, routing decisions to humans, and maintaining an audit trail. Waxell provides both: Waxell Observe captures full execution telemetry, and the governance engine enforces policy in real time before the next step runs.
How do you govern Claude Code or Cursor without changing any code?
Waxell Connect lets teams bring third-party agents — including Claude Code, Cursor, and custom GPT workflows — into a governed workspace with no code changes and no SDK required. Connect works at the coordination layer: registering agents, surfacing their activity, routing decisions to an inbox, and applying MCP governance policies to tool calls. There is no instrumentation step and no engineering work needed to start.
What is MCP governance?
MCP (Model Context Protocol) governance is the practice of applying policy, audit, and access controls to the tool calls made by AI agents through the MCP layer. Because MCP tool calls happen at the agent's discretion — not through a human-initiated request — they introduce new attack surface: tool description changes (rug pulls), PII leakage through tool inputs, and unauthorized capability access. Waxell Connect's MCP governance layer monitors every MCP tool call, checks it against active policies, scans for PII, and logs it to the audit trail.
How does Waxell compare to LangSmith for AI agent monitoring?
LangSmith is an observability tool for LangChain applications — it captures traces and runs for LangChain-based agents. Waxell instruments 200+ libraries across every major LLM provider, vector database, and agent framework, not just LangChain. More importantly, Waxell adds a governance layer that LangSmith does not have: runtime policy enforcement, human-in-the-loop approvals, cost budgets, PII detection, and kill switches — enforced during execution, not reviewed after. For teams not 100% on LangChain, or teams that need governance rather than just observability, Waxell is the broader solution.
What is Waxell Gateway?
Waxell Gateway is the governance layer for AI agent tool use through MCP. It replaces every upstream MCP configuration with a single governed URL per tenant — applying policy checks, PII scanning, and human-in-the-loop approvals to every tool call before the agent gets a response. It works with Claude Desktop, Claude Code, Cursor, and any MCP-compatible client, covers 160+ upstream connectors, and maintains a durable audit trail of every tool interaction. No code changes required — one URL swap per agent.
How does Waxell Endpoints discover shadow AI without decrypting traffic?
Every AI request — whether from Claude Desktop, Cursor, ChatGPT, or a browser assistant — crosses the device's network stack over HTTPS. Waxell Endpoints reads the plaintext hostname from the TLS handshake (the SNI field) without decrypting the connection. This tells you which process is calling which AI provider, when, attributed to which user — all without seeing prompt or response content. Payload capture is a separate, opt-in capability that can be enabled per provider with on-device PII redaction.
The teams that govern AI well now will be the ones trusted to scale it.
Waxell is how you build that foundation.
2-line setup. Works with any Python agent framework.
FAQ
What is AI agent governance?
AI agent governance is the practice of controlling, monitoring, and enforcing policy over AI agents running in production — covering what they're allowed to do, how much they're allowed to spend, what data they can access, and who can override or halt them. Waxell implements AI agent governance through a runtime policy engine that evaluates agent behavior before each execution step and returns structured enforcement: retry, escalate, or halt.
What's the difference between AI agent observability and AI agent governance?
AI agent observability is the ability to see what an agent did — capturing traces, LLM calls, tool invocations, token usage, and decision points. AI agent governance is the ability to control what an agent can do — enforcing policies, blocking actions, routing decisions to humans, and maintaining an audit trail. Waxell provides both: Waxell Observe captures full execution telemetry, and the governance engine enforces policy in real time before the next step runs.
How do you govern Claude Code or Cursor without changing any code?
Waxell Connect lets teams bring third-party agents — including Claude Code, Cursor, and custom GPT workflows — into a governed workspace with no code changes and no SDK required. Connect works at the coordination layer: registering agents, surfacing their activity, routing decisions to an inbox, and applying MCP governance policies to tool calls. There is no instrumentation step and no engineering work needed to start.
What is MCP governance?
MCP (Model Context Protocol) governance is the practice of applying policy, audit, and access controls to the tool calls made by AI agents through the MCP layer. Because MCP tool calls happen at the agent's discretion — not through a human-initiated request — they introduce new attack surface: tool description changes (rug pulls), PII leakage through tool inputs, and unauthorized capability access. Waxell Connect's MCP governance layer monitors every MCP tool call, checks it against active policies, scans for PII, and logs it to the audit trail.
How does Waxell compare to LangSmith for AI agent monitoring?
LangSmith is an observability tool for LangChain applications — it captures traces and runs for LangChain-based agents. Waxell instruments 200+ libraries across every major LLM provider, vector database, and agent framework, not just LangChain. More importantly, Waxell adds a governance layer that LangSmith does not have: runtime policy enforcement, human-in-the-loop approvals, cost budgets, PII detection, and kill switches — enforced during execution, not reviewed after. For teams not 100% on LangChain, or teams that need governance rather than just observability, Waxell is the broader solution.

Waxell
Waxell provides observability and governance for AI agents in production. Bring your own framework.
© 2026 Waxell. All rights reserved.
Patent Pending.
Waxell
Waxell provides observability and governance for AI agents in production. Bring your own framework.
© 2026 Waxell. All rights reserved.
Patent Pending.
Waxell
Waxell provides observability and governance for AI agents in production. Bring your own framework.
© 2026 Waxell. All rights reserved.
Patent Pending.