
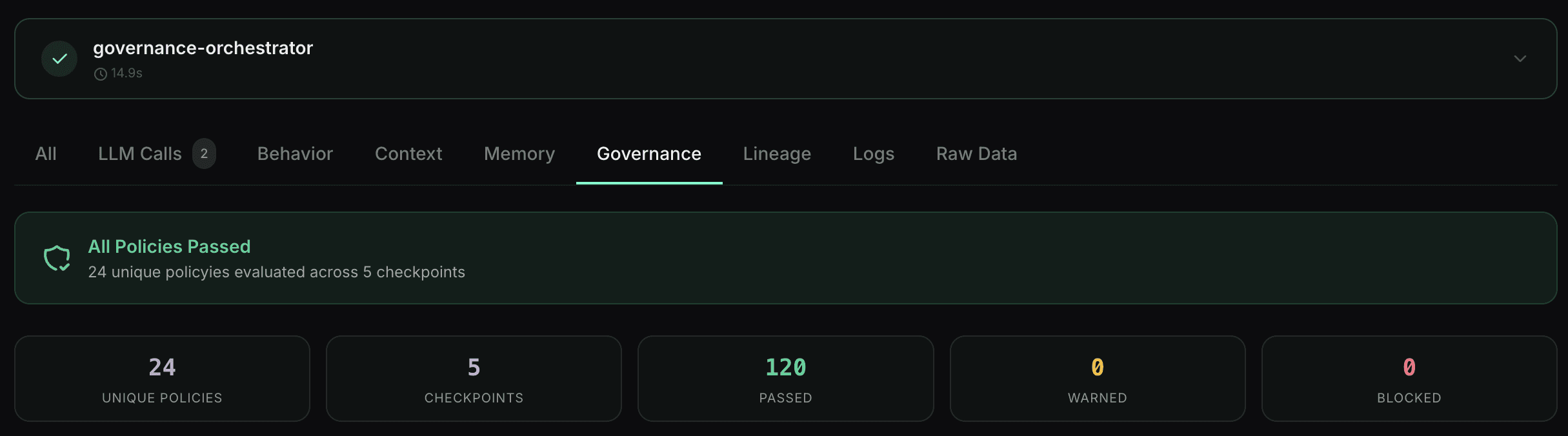



What Can Waxell Govern?
50+ policy categories. Each one is a class of problem you no longer solve with hope. Configure rules in the dashboard, enforce them during execution.
How Do I Add Observability to My Agents?
Two lines of code. Every LLM call, tool invocation, and agent decision — captured automatically from that point on.
As easy as pip install.
Install the SDK. Set your API key. Initialize before your imports. From that point on, every LLM call, tool invocation, and agent decision is captured automatically — with cost, latency, and token counts attached.
No decorators required to start. No wrapper classes. No changes to your agent logic. When you need more structure, add decorators and context managers incrementally. Governance, scoring, and prompt management are there when you're ready.
Works with any Python agent framework. Supports sync, async, Jupyter notebooks, and production servers. If your agent runs Python, you can observe it.

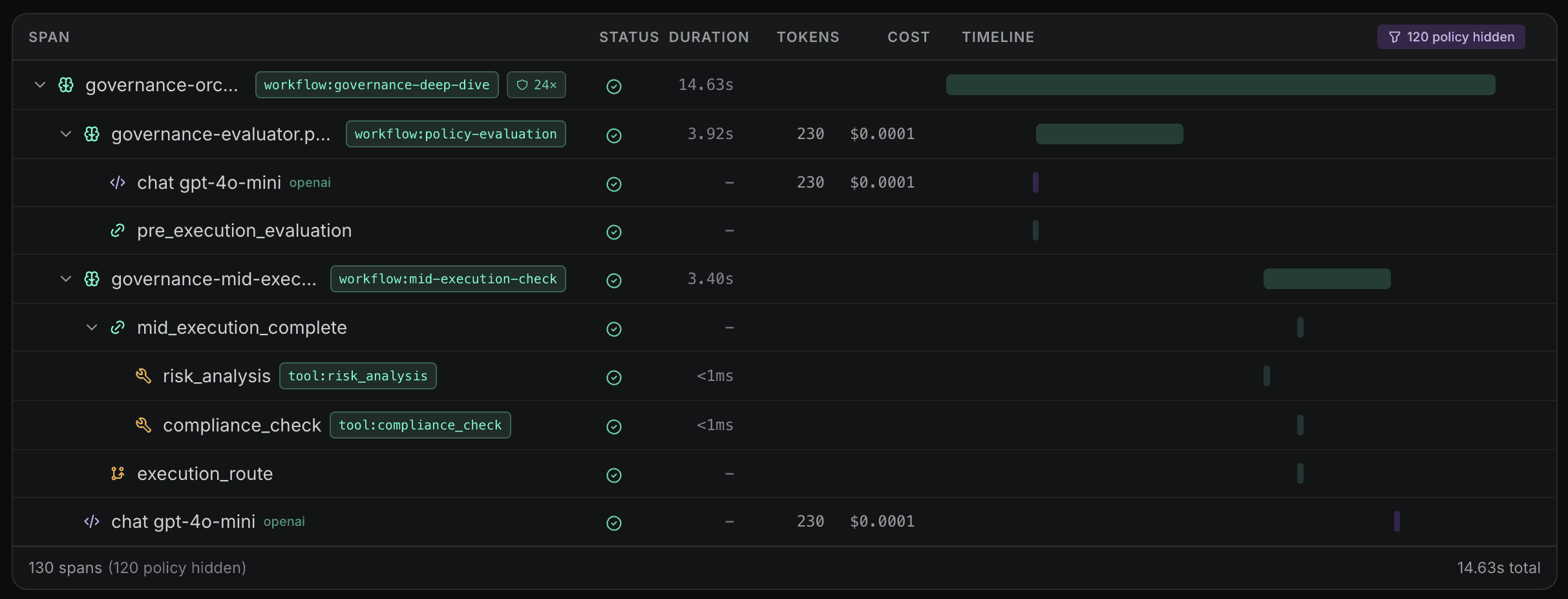
Waxell Observe captures the full anatomy of an agent run — not just the output, but every decision that led to it. LLM calls with tokens, latency, and cost. Routing decisions with the options considered and the choice made. Chain-of-thought reasoning. Retrieval queries and relevance scores. Tool calls with inputs, outputs, and timing. Full execution trees with parent-child span relationships, powered by OpenTelemetry.
None of this stays in a dashboard. It feeds directly into the Waxell governance plane — where policies evaluate agent behavior in real time. Before execution, between steps, and after completion. When a policy triggers, the agent receives structured feedback: retry with adjusted parameters, escalate to a human, or halt.
Observability without governance is an autopsy. Waxell makes it a control system.
How Does Waxell Observe Work With Multi-Agent Systems?
One coordinator, three planners, twelve tool calls — and you can see every branch, every handoff, every decision in a single trace.
Production agents don't run alone. A coordinator dispatches to a planner, which spawns researchers, which call tools. Waxell Observe traces the full tree — every child agent, every span, every decision — linked by session and lineage.
Parent-child relationships are detected automatically. Session IDs, user context, and the observe client propagate through nested calls without manual wiring.















FAQ
What is Waxell Observe?
Waxell Observe is an observability and governance SDK for AI agents running in production. It auto-instruments Python agent frameworks — capturing LLM calls, tool invocations, decisions, and costs — and enforces runtime policies that control what agents are allowed to do next. Two lines of code to initialize; no changes to agent logic required.
How does Waxell Observe differ from LangSmith or Langfuse?
LangSmith and Langfuse capture what agents did — they are observability tools. Waxell Observe does that too, but adds a governance layer: runtime policies that evaluate agent behavior in real time and return structured feedback (retry, escalate, or halt) before the next step executes. The distinction is observability versus governance: recording what happened versus controlling what happens next.
What can Waxell Observe govern?
Waxell Observe supports 50+ policy categories, including Audit, Content, Control, Cost, Kill, LLM, Operations, Quality, Rate-Limit, Safety, and Scheduling. Each category addresses a class of production risk — from runaway spend and prompt injection to silent failures and unauthorized model access. Policies are configured in the dashboard and enforced during execution, not reviewed after the fact.
How does Waxell Observe work with multi-agent systems?
Waxell Observe traces full agent execution trees, not just individual calls. In multi-agent systems, parent-child relationships between agents are detected automatically — every child agent, every spawned workflow, and every tool call is linked by session and lineage. Session IDs and observability context propagate through nested calls without manual wiring.
Does Waxell Observe work with my existing Python agent framework?
Yes. Waxell Observe auto-instruments 200+ libraries — including LangChain, LlamaIndex, CrewAI, OpenAI, Anthropic, and most major vector databases and infrastructure tools. Initialize the SDK before your other imports and instrumentation begins automatically. No decorators required to start, no changes to your agent logic. Works with sync, async, Jupyter notebooks, and production servers. Agentic governance begins from the moment you call waxell.init() — nothing else needs to change.
What does "dynamic governance" mean for AI agents?
Dynamic governance means policies are evaluated in real time during agent execution — not applied as static pre-filters or reviewed after runs complete. It is the core of what separates agentic governance from traditional observability: rather than recording what agents did and alerting afterward, Waxell evaluates each decision point against configured policies before the next step is allowed to proceed. When a policy triggers, the agent receives structured feedback — retry with adjusted parameters, escalate to a human, or halt execution immediately.